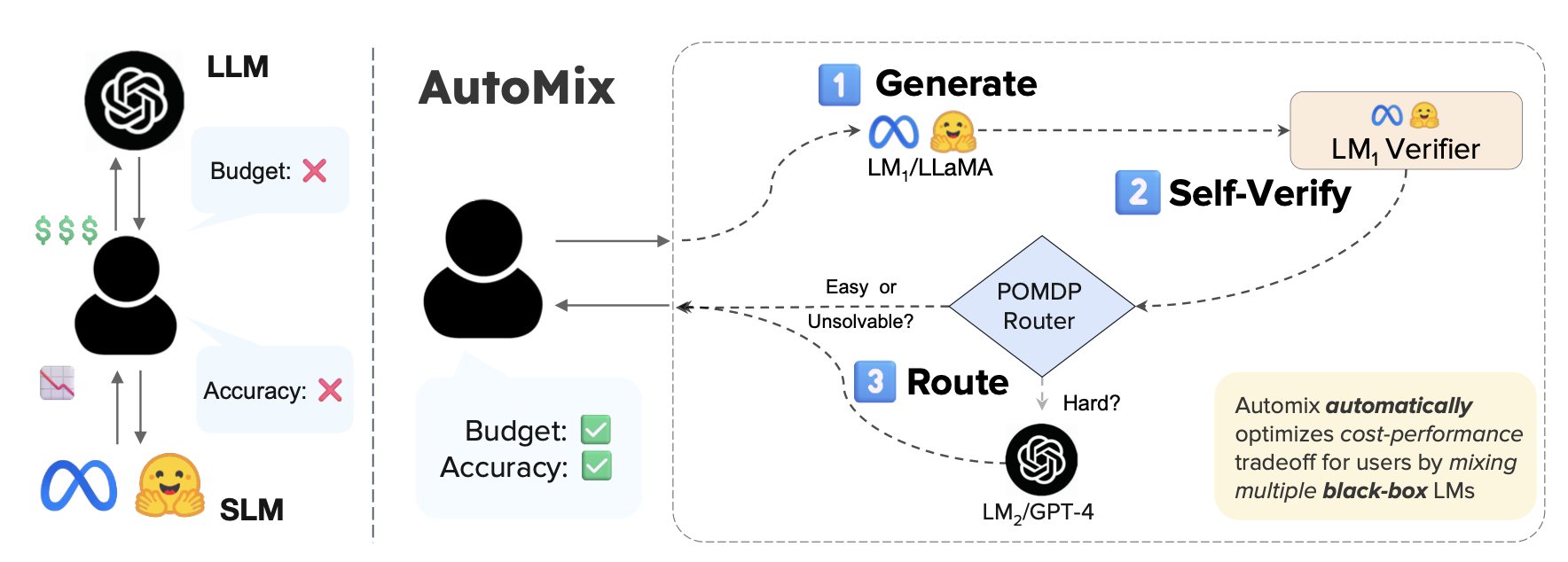
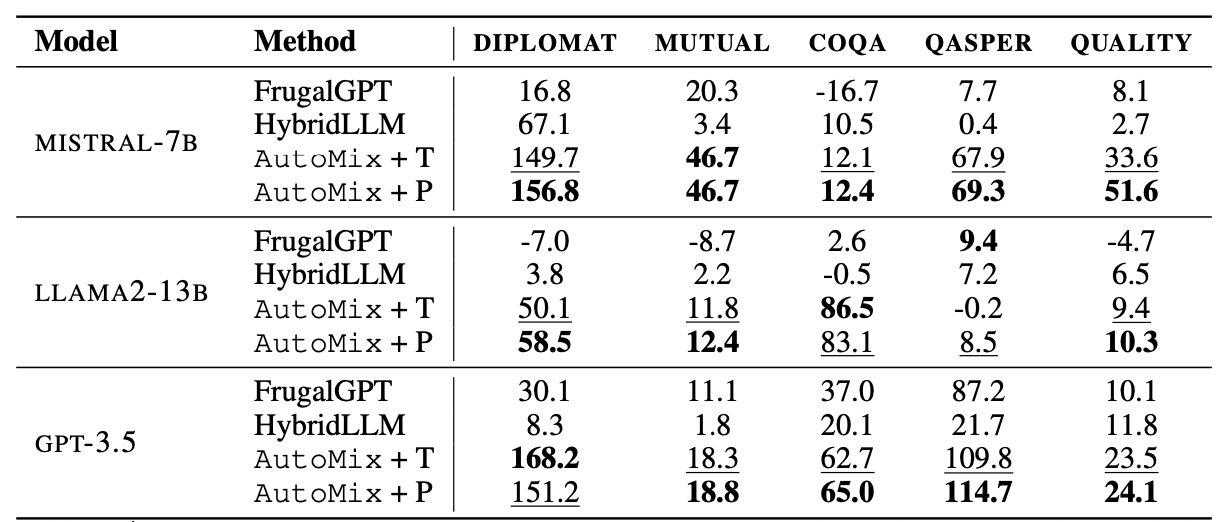
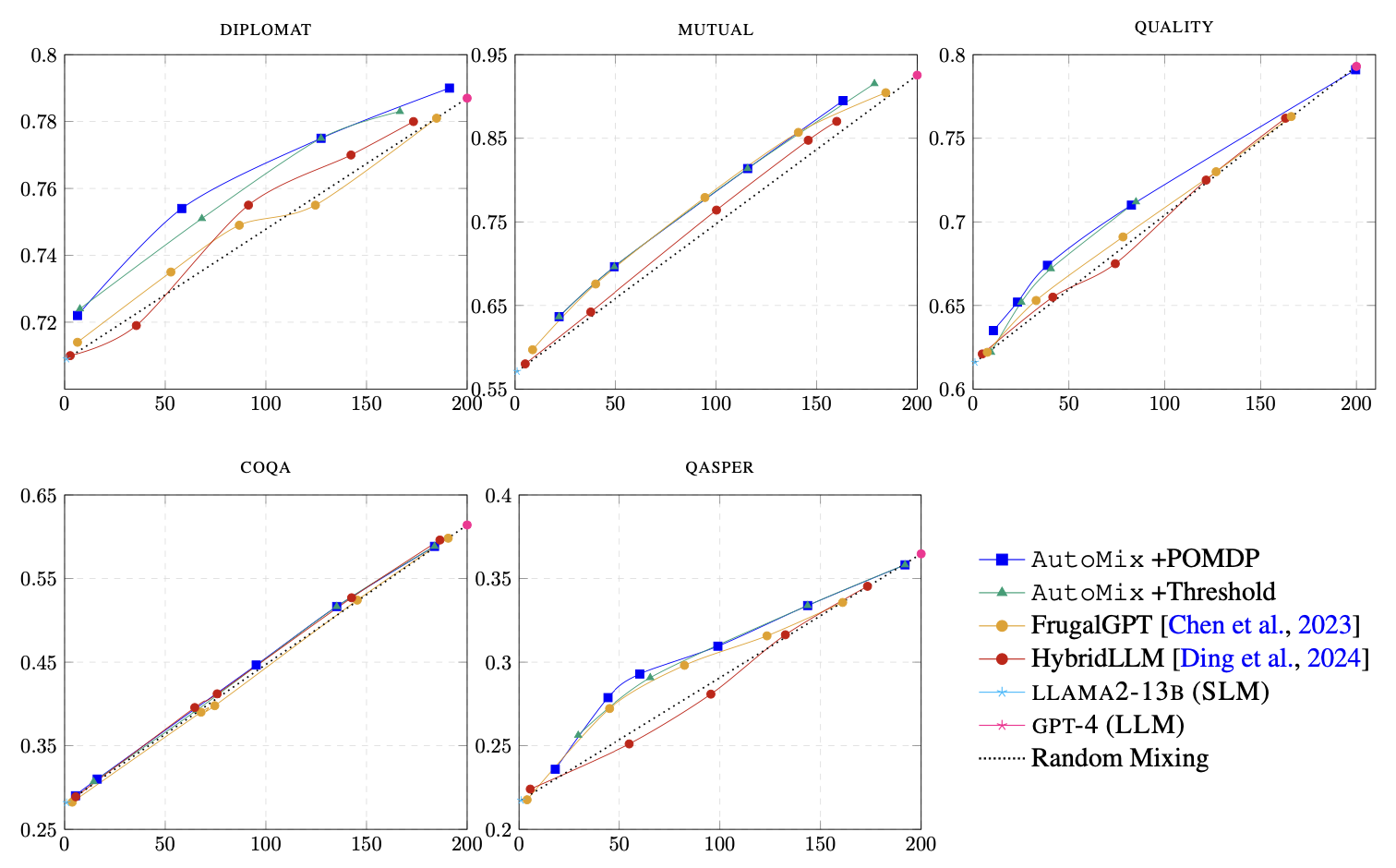
Large language models (LLMs) are now available from cloud API providers in various sizes and configurations. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix are two key technical contributions. First, it has a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring extensive training. Second, given that self-verification can be noisy, it employs a POMDP-based router that effectively selects an appropriately sized model based on answer confidence. Experiments across five language models and five challenging datasets show that AutoMix consistently surpasses strong baselines, reducing computational cost by over 50% for comparable performance.
1. Installing
pip install automix-llm2. Training and Inference
from automix import Automix, POMDP
mixer = Automix(POMDP(*args, **kwargs))
mixer.train(train_data)
results = mixer.evaluate(test_data)3. High Customizability
Check out our Github repo for more details!@misc{aggarwal2024automixautomaticallymixinglanguage,
title={AutoMix: Automatically Mixing Language Models},
author={Pranjal Aggarwal and Aman Madaan and Ankit Anand and Srividya Pranavi Potharaju and Swaroop Mishra and Pei Zhou and Aditya Gupta and Dheeraj Rajagopal and Karthik Kappaganthu and Yiming Yang and Shyam Upadhyay and Manaal Faruqui and Mausam},
year={2024},
eprint={2310.12963},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2310.12963},
}